
January 2025: Coding agents are for everyone
Claude Code is for you, and you, and yes, definitely you.


I wrote previously that synthesis is a new bottleneck because I observed my production capacity, expanding as I adopted coding agents[5] for more and more tasks.
This is based on my experience, dramatically expanding my own capacity, understanding that something new is happening and trending, and trying to grapple with the implications. I’ve read some pushback basically saying “if you’re so productive what did you actually ship”. The critics have a point, but miss one as well. Some personal examples are below.
Lots of what I spend time doing is making good decisions and applying judgement. In this context shipping more stuff to customers is one kind of victory. Improving the quality of decisions (inputs) is another (quite valuable) kind of victory. A lot of what coding agents have helped me do is get to more decisions more quickly and in a lot of case better decisions that I have higher conviction in earlier than I would otherwise.
You can execute a task without understanding it; you can press the button you’re told to press, and so can a computer. The process of synthesis: understanding what a thing is, why, the implications and second order effects, the decision that needs to be made; someone needs to do that. Someone needs to be accountable for it, be correct, take responsibility when it doesn’t work, and place it in the context of the organization or mission you’re executing upon.
When you own outcomes, better decision making is insanely valuable. When you’re trying to build something at all,, to build something differentiated, compelling, that breaks through and be responsible for a success or failure - you live and die by decision quality. If people using coding agents never shipped a new feature to customers (unlikely) but all made even 5% better (or faster) decisions, that is a humongous amount of leverage being created. [3]
Coding agents are for everyone
I used to think of coding agents as a tool for coders/developers/engineers. I now think coding agents are tools for everyone. Every human and every organization has some set of things they want to do where they’re operating at the edge of the software available to them. Coding agents make it possible to either do really customized, niche specific things, or extend the software to a niche or custom or emergent use case.
I’m still trying to articulate the types of tasks that I’ve been finding success with. I haven’t yet explored everything that’s possible, and it’s also likely that the exact shape/parameters of the tasks that are legible to this approach is rapidly changing and expanding.
The best way I can think to describe it is -if a task can be done entirely on a computer, it’s probably legible to a coding agent. If you have a task that is tedious and repetitive and, and the data used in each repetition and the clicks used to perform each repetition are fairly uniform, that task is probably legible to a coding agent . Tasks that used to require technical expertise are far more doable to a coding agent assisted non-technical person. This doesn’t replace most technical people - think of how much time you spend saying “no” as an engineer. Coding agents enable the non-technical people asking the questions, to ignore the “no” and try it for themselves. And that is good![1]
An App for Every Task
So far, my general approach has been
Describe the problem. This can be very low fidelity; more detail is better, but a single line can often be enough to start
Rely on the planning agent to shape the idea and extract precision
One challenge I see here is to date, most of my interactions with planning agents haven’t extended beyond 4 or 5 questions. I suspect that if the gap between your starting point and a sufficient answer requires more than four or five questions to gain precision, your outcomes will be less optimal or take longer. More specificity is better upfront, but don’t let thorough be the enemy of getting started.

Second, I’ve begun to think of my use cases in terms of apps. Anytime I have a task to do. I describe the outcome I want, and ask it to build an app or a dashboard that lets me
Track what’s being built
Once built, track what’s being done
Validate the task meets success criteria
This approach enriches the feedback I give in the session. Viewed through this lens, every time I’m doing a task. I’m also building an app to QA the task and the output.
A few tactical examples:
Finders: I’ve built several tools that will search the Internet for a common type of artifact for a common type of entity that’s not centralized. These could be things like EDI companion guides, medical necessity policies, regulatory language on a specific topic and so on. I aggregate these for analysis in a later step (usually also assisted by a coding agent).
Structure Extraction: Taking a large corpus of PDFs from a variety of sources, extracting common values and comparing them for analysis. For example, comparing the medical necessity criteria amongst different payers and plans, or comparing state regulations affecting patient billing and reimbursement. 2 different payers (or 2 different plans from the same payer) might require different prior treatment before authorizing a specific procedure - cutting agents provide a way to scale that discovery.
VLOOKUP on steroids: my most frequently used function in google sheets is VLOOKUP. It’s great if the keys in both data sets are structured and clean. If either is diverse or messy or they come from different systems of record, I can now easily create a python script to probabilistically find relationships, use examples to flesh out different matching strategies, and generate a UI to review the results, fix incorrect matches, observe errors and generally ensure the app is doing what I actually intended. In this context, the UI is deeply not important. What is important is the coding agent gives a visual interface to manipulate its output.
DIY API: in a lot of cases you have Zapier. But when you don’t or when you’re working with data that’s privileged in some way, you can have Claude code build you a translator. In my case, I’ll sometimes use a tool like granola to transcribe meetings and generate action items and I built myself a custom Apple shortcut automation that every day grabs all my action items out of granola and pushes them into my Apple notes, which is much closer to my system of record For tasks. Again, vanishingly simple if you’re an engineer, but completely opaque otherwise.
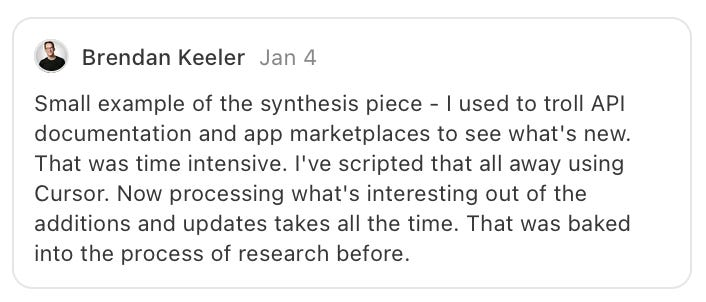
If there’s something you’re trying to do and the service you’re trying to do it with has an API you can have Claude code build the API integration for you to scale an activity you already do by hand, and give you a customized UI to yourself to interact with it. Brendan Keeler shared an example after my last post of something he built was Court listener:
Implications and opportunities
There are a ton of second order effects if you get mass market adoption of coding agents.
Browser w/Coding agent:I think there’s an opportunity for a new type of browser that is natively has a tooling like recording + coding agent specifically to build tools around repetitive tasks on behalf of users. This would be like a combination[2]
Reasoning model that observes what you’re doing and tries to proactively make sense of it. There’s nothing really like this out there - I tried ChatGPT Atlas hoping for this and even agent mode doesn’t have something that assists you with automations.
Planning agent that sketches out how to automate it and explores APIs/MCPs that could help
Cloud infra to give your automations a stable home over time (like a combo of git + Vercel + Kernel[4])
Single task apps: We’re firmly in the era of throwaway single task apps. I’ve built and thrown away a dozen in the last month alone. I don’t think most of these will replace my SaaS usage, but maybe that’s just me. It’s currently so dramatically cheap to build an app that’s extremely custom to you, that just does one thing well (its literally been faster to do this than to brute force it, and in many cases with way better results)
Generative software: This is pretty hard to visualize but I think there is a concept of generative software that’s pretty interesting. I think of this like your SaaS that self molds to each specific users workflow so that the core remains the same and meets all your SLAs and things that need to be true and the interface molds itself around the user, gradually over time based on frequent usage patterns, support tickets and direct user requests (eg the user could specifically ask the software for a feature and get it right away. This is different from generative UI like Monogram [4] where the UI adapts to the task. This is more like the functionality molds around how the user works to extract the most usage out of them (imagine a world where addictive SaaS exists).
Self healing software: I think there’s also going to be something I call self healing software. This is where if you build something that generates results, you use a coding agents to not only improve those results, but to improve the software itself using this system’s data exhaust, your feedback etc. This is one of the paths we’re pushing on at Substrate.
Secrets Handling: I think we will see many more secrets leaked in the wild, and I think there’s an opportunity to create consistent secret handling tools so that anyone using a coding agent can have tools to safely handle secrets by default (instead of depending on users knowing what they’re doing bc they mostly don’t). Before the era of coding agents, I wrote about agent authentication problems. Mass adoption of coding agents expands the surface area and makes this even more acute; now not only can you leak passwords, you can leak API keys (which can often enable machines to exfiltrate more data faster, or spend down your credits).
Credentials: Related to handling secrets, a secondary thing I didn’t anticipate was how to safely handle credentials in the context of being able to turn every task into an app. In my case for example, when building something thats a browser automation, I ask it to include a 30 second wait at the start, so I can log in manually before enabling it to continue the remainder of the automation. Haven’t had to do this all that much, but extremely clunky.
The good APIs will win: Products (particularly systems of record) with good API coverage and documentation will probably extend themselves. This is because their users will be much more able to customize the system of record than previously was true at lower cost, and much more reliably. As a result, human users will be able to drive machine scale usage (along with the attendant spend, stickiness etc)
The consultants will be fine: In the short term, while this arbitrage exists, all manner of consultants are going to kill it because they’re going to appear far more impressive and become far more productive for their clients, simply because they incorporate coding agents into their workflow, while a client’s IT department spends multiple quarters debating whether to grant a ChatGPT license.
Maintenance & consistency; while its gotten a lot easier to build and output/throughput will increase, a lot of the overhead in software is maintenance and adaptation, patching etc, in addition to having a sense for what types of builds/code will be easy to maintain.
Measurement: this isn’t strictly a problem for coding agents. I think it’s true for all large language model powered products, but just understanding who in the organization is using these products, where they’re getting utility, what usage patterns are working, how much you’re spending, and whether the ROI is there is going to be really important. Larridin [4 is working on this problem, but today, the vast majority of companies are absolutely terrible at understanding how their employees are using large language model powered products. It won’t get better by itself.
Coding agents for non coders: all the coding agent tools are primarily accessible in IDEs (you can also access Claude Code via the Claude prompt interface). Most non engineers don’t know what an IDE is. Someone’s going to make a killing figuring out the right interaction paradigm for non engineers to access coding agents, including instructions, planning, QA, deployment, maintentance etc. In a way, if a non-code has to see code, the product is actually incomplete. Maybe its just Claude (with CoWork)?

Where this doesn’t work
Just observing my workflow the last few weeks I’ve found this dynamic most pronounced wherever I have something repetitive to do and each rep has >80% overlap in fields/values/clicks.
Whenever the substance of each repetition diverges, this breaks down. I recently had to create logins for hundreds of different websites and tried a few times building something to assist me. I just couldn’t get something done that would’ve been faster than doing each by hand. To date this is the only thing I’ve tried where I haven’t been able to get at least some lift from using a coding agent. Of course, there are a bunch of things that I do by hand because I want to or because they are not sufficiently repetitive that the payoff would be there. But to date almost everything I’ve tried to do (even things that I thought would be on the edge) that meet the above parameters have seen some kind of improvement. I read this as; as a non-engineer, I’m probably not good at telling what tasks would be susceptible to coding agent based approaches, so I should cast a wide net.
What this feels like
The two horizontal tools that basically every knowledge worker uses daily are
A word processor (Google Docs or Microsoft Word), for qualitative work (eg communication)
A spreadsheet (Excel or Google Sheets) for quantitative work (analysis & computation)
Analysis in the context of knowledge work means; you have some data, and you’re trying to make sense of it and understand what it means for a decision. Think of most times you’re in a dashboard and you hit “Export CSV”. The downstream task is usually some kind of analysis. Computation in this context means there’s a process you have to regularly execute, and the spreadsheet is the “rules engine” for that process. An example of this is month end close in accounting; a bunch of data is rolled up into some spreadsheets at the end of the month, and someone reviews by hand to make sure things look right and anomalies are accounted for, but the spreadsheets are doing the computation (it literally contains the formulas and relationships) and a human is reviewing them, rather than a human doing the computation themselves.
I mentioned before that spreadsheet work is “coding adjacent”; you need to be able to think logically, understand functions and formulas and how they relate to each other, you can build really complicated workflows in spreadsheets, and all this is possible without being a software engineer. But the reality is there’s probably as wide a distance between a beginner excel user and an expert, as there is between me and a 10x engineer (long before coding bootcamps were a thing, investment banks used to have excel bootcamps for incoming analysts).
I think being able to use a coding agent well will be similar to being able to use a spreadsheet well; horizontally required for all knowledge workers, to assist in the computation & analysis part of the job. Being good at it might not make you a 10x engineer, but will be a force multiplier vs. those who are not. In this way, I think the coding agent is the successor to Excel.
Thanks to Nikhil Krishnan and Jesse Wilson and Brandon Carl for reading in drafts.
[1] This is a double edged sword in a good way. As an engineer, you’re now gonna have to face some vibe coded prototype that completely elides a really good reason not to do something. On the other hand, as a non-engineer, it is now going to be super hard to justify why you showed up without a prototype. Not prototyping, not thinking through the questions, experience, edge cases and technical challenges is going to become a huge red flag. The bar is just . . . higher.
[2] the cursor browser tool is the inverse of this - it’s a coding agent with a browser stapled to it. Extremely useful for engineers, but from what I can tell not built to scale browser automations. I think the reverse will be just as useful for non-engineers.
[3] my point here is not that everyone will make better decisions. My point is that measuring productivity exclusively in terms of apps or features shipped misses a whole dimension of what it means to be productive.
[4] I’m involved in these companies either as an investor or advisor.
[5] So far I’ve tried Codex, Composer and Claude Code. Claude Code has been most impressive, but I assume over time they won’t be the only game in town. In addition, I think it’s pretty important to try new tools - the capability of these things is changing so much that I don’t think the existing interaction paradigms are the only ones that will work well.
—
Unrelated - I’m hiring at Substrate (www.substrateintelligence.com). If you’re load bearing and interested in working on thorny, deep in the stack problems, learn more here.
Great read. I see what you did there with the title. 😏