
January 2024: What if ACH had attachments?
The value of a high bandwidth payment network

One way I think of payments innovation is how counterparties exchange information, vs how counterparties exchange value. Sometimes, the information around the payment, and how it’s exchanged, is nearly as valuable to solve as the exchange of value itself. This is especially true for many b2b payments.
“How counterparties exchange information” here means “how does the sender specify a recipient? What instrument does the sender specify? Is it the final instrument or is it an “alias” of that instrument?” In the card network world, this function is called “clearing” [1]. For this essay I’ll describe it more generically as the messaging layer. For ACH transactions, NACHA is the messaging layer, and the account and routing number are instruments. For card network transactions the card networks are the messaging layer, and the card number is the instrument. For Venmo, Venmo is the messaging layer, and your phone number, email address or handle can all be instruments (and they’re all essentially pointers to the same place). For Zelle, Zelle is the messaging layer, and your phone number is the instrument.
“How value is transferred” here refers to the system that the ledgers of the counterparties institutions use to “say” that they are “done” or that the payment is complete or “settled”, and there are no exceptions and no one needs to follow up. In the card network world, this is called “settlement”. For this essay I’ll describe it more generically as the money movement layer. For ACH transactions, debit card transactions and Zelle, ACH is also the money movement layer (I believe for signature/dual message card transactions they are settled via FEDWIRE not ACH, but not sure what the rules are on when one is used vs. another). For Cash App peer to peer payments (P2P), PayPal P2P, Venmo P2P, and other closed loop networks, value transfer is all on ledger/inside the same database.
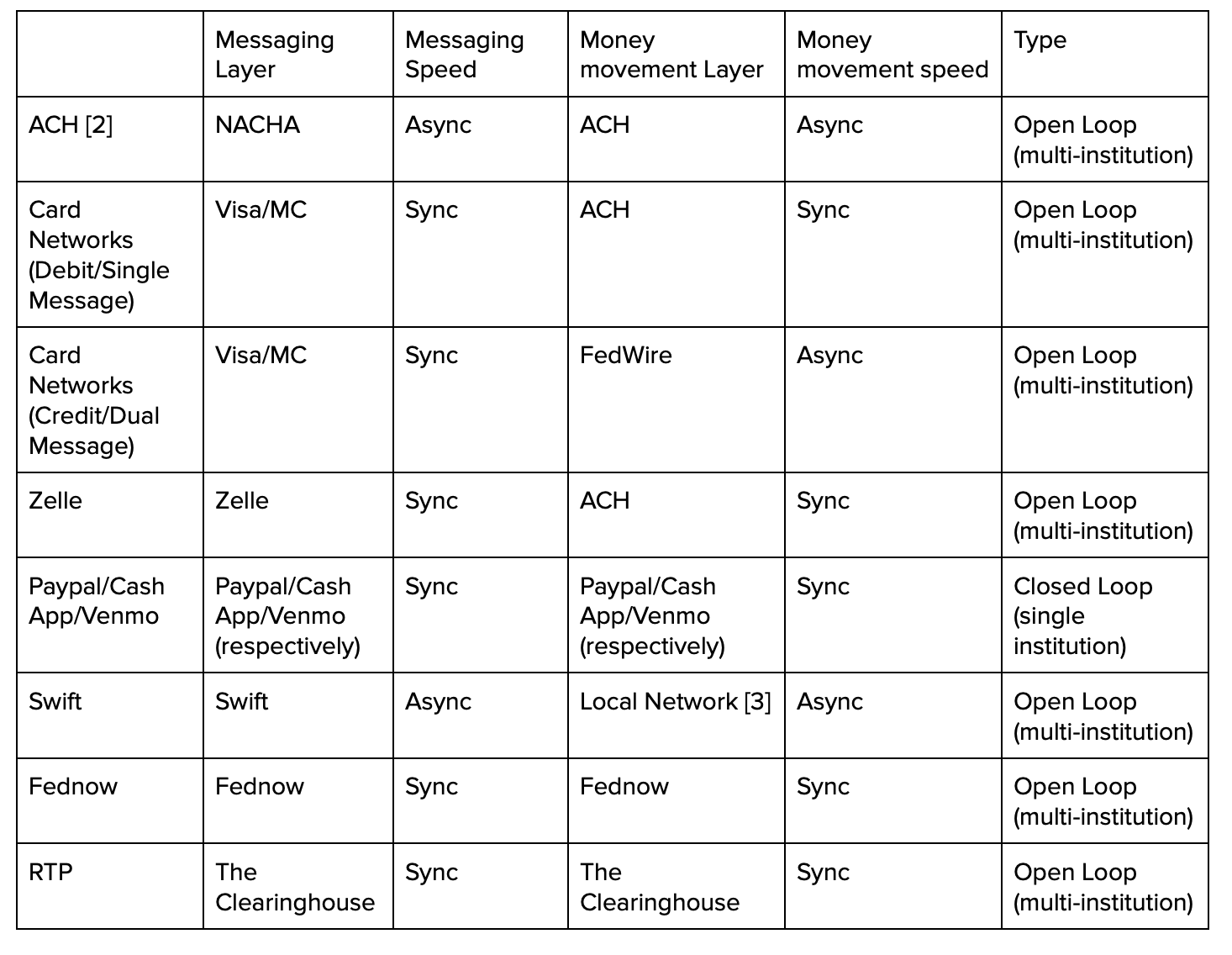
How parties communicate is the messaging layer, and how value is transferred is the money-movement layer. In closed loop environments, the distinction between the messaging layer and the moneymovement layer matters less, because there’s only one institution on both sides of the payment (even though the counterparties might be different) so there’s no issue where two institutions have to agree about the rules. When two separate entities have to shake hands, it matters so much that multiple trillion dollars in market cap exist to solve this problem, coordinate transactions, resolve exceptions, and so forth.

Over the last 2 decades, payment innovations first optimized speed, and now cost
Roughly speaking, innovations in payments over the last 2 decades optimized speed. In the 2000s, Paypal, Authorize.net, and eventually Adyen and Stripe brought payments online. In the 2010s, Cash App, Venmo, (enabled by the card networks via the Visa OCT and MasterCard Send transaction types, and a bevy of PIN debit networks) focused on making consumer payments fast. Now FedNow and RTP are focused on making wholesale payments fast and cheap. All of these benefit from the tailwind of offline payments coming online and being digitized (checks are still ~21% of non-cash payments [4] at over $27 trillion). These innovations have sometimes traversed only the messaging layer, sometimes the moneymovement layer, and sometimes both, but the objective has been to ensure that the recipient of funds has access and is able to use their funds earlier than previously possible.
The next constraint in the messaging layer is bandwidth
Despite all the innovation over the last 2 decades, the messaging layers have remained bandwidth constrained. In card and ACH payments the “statement descriptor” is the entirety of content you can pass along with the payment (other than necessary metadata such as the instrument, time, amount etc).
Despite this, many payments have actually a wealth of metadata that “wants” to be communicated along with the payment. Pre-internet, this metadata was exchanged with paper (faxes, letters etc). Today, this metadata is typically exchanged via a parallel system. In a lot of cases its email, but for sufficiently specialized areas at scale, external, third party systems have been developed to handle the exchange, and in many cases companies are formed around these systems. Exchanging this metadata is important because lots of business processes inside a company rely on it for decision making, and to prevent errors.
For example, when companies are paying vendors or suppliers, itemized invoices are typically exchanged over email, and payment is executed by ACH, check, or wire. Imagine paying a vendor without knowing which invoice its for? Imagine paying an invoice without knowing which specific services you’re paying for? How will the sending party know where to attribute the costs? How will the receiving party know which accounts receivable to attribute the payment to? How will tax reporting occur?
For healthcare claims in the US, payments are typically via ACH or check, and claims data is typically via 835/837 files. In consumer payments, receipts are exchanged via text, email, physical paper or your app, but payment is executed by card (or paypal or whatever payment network the consumer chooses). The opportunity here, if the messaging layer had more bandwidth, is to include the metadata inside the payment instructions directly. There’s a variety of benefits to doing this. Among others . . .
You could authorize directly on specific items, rather than on the whole payment
You could automatically reconcile payments against their purpose, rather than relying on parallel systems to do so
You could explicitly include post-payment context (eg this payment is HSA/FSA eligible, this payment is eligible as a childcare savings payment, 30% of this payment is a tax deductible business expense in category X, etc)
The bandwidth constraint in the messaging layer creates a handful of problems that people don’t typically associate with payments, mostly around accounting and operational reconciliation of various forms. I’ll use two examples to illustrate these.
Example 1: Healthcare claims, 835/837 files and BAI files
In US healthcare, when a patient visits a provider and the provider submits the claim to the patient’s insurer, the insurer typically pays via physical check or ACH. Lets say Jane visits her primary care physician for her annual physical. The PCP submits Jane’s claim to United Health for $300. United reviews and adjudicates the claim, and says Jane’s PCP is owed $125 for the entirety of the visit, after the claim is fully adjudicated. When United Health pays Jane’s PCP, they do the following:
They send an ACH of $1476 (or another arbitrary amount) to Jane’s PCPs bank account
They also send an 835 file which will include (among other things):
How much was paid in total
How much Jane owes, and whether it’s her copay, deductible, co-insurance etc
Which procedures were covered by Jane’s insurance, and which were not
An ID which says exactly which payment the claim was paid in (this would typically be a check number or a payment trace id)
They also send a document, either directly as a BAI [5] file, or one that can be converted. This file maps to the ACH of $1476, and includes (among other things)
An identifier for every claim that is being paid as part of this transaction (because the $1476 is an aggregation of multiple claims being paid, instead of each being it’s own payment, which would be simpler from a reconciliation standpoint)
A dollar amount to map to each identifier (so amounts can be tied direclty to claims)
A service provider for the PCP, or an employee, looks up the 835 file, ensures where is a matching ACH in the bank account associated with the payment ID, and marks the claim in the the PCPs system of record as paid. Sometimes this is automated, and sometimes it’s manual, and often its just not done.
At the low end, doctors offices often don’t even interact with this. They just don’t know. At the high end, healthcare providers will typically use a receivables management service (often owned by their bank) to help tie the specific claim to the specific payment it came in, ensure that the amounts tie out, and so forth. You’ll notice here that in addition to the payment itself, there’s a LOT of data being passed between the payer and provider, that essentially traverses a side channel [6]. For Jane’s PCP provider to ensure they’ve been paid, they now need to reconcile the payment. In healthcare this is called payment posting or claim posting; entering into your system of record that a particular claim has been paid, and how much was paid, and when, how, and by whom. Because of how mission critical this is, and how often this process fails, many healthcare organizations, in addition to paying a service provider for this, have huge teams of people who manually help reconcile payments and manage (the multitude of) exceptions which occur.
By expanding the bandwidth in the payment, all the information required to reconcile the payment, could be included directly in the payment itself, instead of being passed through a side channel. If you had this, you wouldn’t need the side channel, and a lot of the expense associated with reconciling payments would collapse as you no longer need to maintain the side channels, require fewer hires to manage exceptions and so on.
Example 2: Expense categorizations for tax deduction
A workflow any small business owner or 1099 worker is familiar with is:
Spend $300 on a variety of items
Save receipt
Enter expense into your tax accounting system (often Quickbooks, I’m biased but I use Found), and
Categorize the transaction (eg Airfare vs. Business Meals vs Subscriptions)
Take a picture of the receipt
Tens of millions of Americans go through some version of this process every month. The transaction needs to be categorized because that determines how large your deduction is for tax purposes. The receipt needs to be stored because that substantiates that it indeed was a business expense that was eligible for the tax deduction in the first place (this matters most if you get audited by the IRS, because without substantiation, you’d end up owing more taxes and possibly interest and fines on top of the taxes.)
The categorization step, and the receipt capture step, are (again) consequences of constrained bandwidth in the messaging layer. If it were unlimited, you could a) pass the entire contents of the receipt, including what specific items were purchased, taxes for those items, and a tax deductible category. This would save the buyer from having to categorize the transaction or store the receipt manually.
These are just two examples of what you could do with unlimited bandwidth in the messaging layer. You can apply this to many other use cases though. In vendor payments, you could pass through the itemized invoice and any accrual or amortization information, which could ultimately pass into each company’s ERP and be utilized for accounting purposes. For p2p transactions, you could pass through rich details on the sender and recipient, and the reason for the transaction. In payroll deposits, you could pass along hours worked and other details of the exact payroll run, which would help reduce wage theft and enable the employee to reconcile against their timecards. For almost every transaction scenario, there’s meaningful additional context that lives outside the payment system. In the highest value cases (mostly corporate) employees and vendors are organized around ingesting, normalizing and utilizing this context, which essentially is a hidden expense that increases the cost of payments and ultimately the services being paid for. In most other cases, we just live with this deadweight loss.
With more bandwidth, payments can reconcile themselves.
To bootstrap this, you’d need a consortium that included a mix of large payment initiators and recipients, banks, and companies that build and run the system of record. This sounds like an awful job, because it means getting a bunch of the largest entities on the planet to agree, which, good luck with that. Here’s a sampling of the parties you’d need at the table:
Initiators: government payors, health insurers, large B2B cos paying suppliers & vendors
Systems of record: Netsuite, Quickbooks, other accounting packages
Payment acquirers: Square, Stripe, Adyen, GlobalPayments etc
Payment operations companies: Modern Treasury, Treasury Prime etc
Banking Cores: Fiserv, FIS, Jack Henry
To make it work, you’d need to think of the network slightly differently than we have in the past. MasterCard describes their function as facilitating interbank clearing and settlement [1]. This network would have to have a way to reach into end systems with necessary context for reconciliation, and give all the parties at the table economics that are clearly better than the corporate overhead they currently spend on this function. For instance, in the example of Jane’s PCP above, the flow would look like:
United Health sends an ACH of $1476 to Jane’s PCPs bank account. In the messaging layer for this payment, they include a list of claims that were paid, and how much was paid specifically for each claim
This is written directly into the PCP’s billing system of record, obviating the need for a service provider or employee to do this work.
This can also be written directly into the PCP’s accounting system of record, also shrinking the accounting burden associated with this claim.
I’ve picked healthcare as my example of choice because I’m fairly familiar with healthcare industry payment workflows, but tons of teams in tons of industries already use this context; they just get it from systems outside of payments. Accounting departments need the categorization for accounting purposes. Customer service teams might need more context on a payment when someone calls and asks about a payment that is late, missing info, or is short. Capital markets teams might need this to investigate discrepancies in payments[7]. In any environment with complex receivables exchanged between sophisticated counterparties, this dynamic repeats itself over and over again[8]. The other crucial difference here is, the network itself has to also be aware of the common accounting ERPs/systems of record counterparties might use, and have specific business logic or rules for writing to those systems (or for ensuring information transmitted across the network is in a write-able format).
Thanks to Saira Rahman, Timothy Thairu, Dimitri Dadiomov, Aaron Frank, and Ryan Lea for helping refine this.
[2] https://www.nacha.org/content/ach-payments-fact-sheet
[3] https://www.moderntreasury.com/learn/what-are-swift-payments#
[4] https://www.federalreserve.gov/paymentsystems/fr-payments-study.htm
[5] https://en.wikipedia.org/wiki/BAI_(file_format)
[6] Also a lot of this would be simpler if payments and claims were just 1:1 instead of aggregated.
[7] The capital markets use case is interesting because as it revolves around gigantic sums of money moving around on a daily basis. The cost of mistakes is so high that there’s reasonable amounts of money to spend on the humans required to resolve exceptions (Saira mentioned repo as a nice example). In the repo case, including the exact securities being used as collateral in the payment message would create an extra layer of validation that the right agreement is being honored.
[8] Protocol changes in payments are hard, take years to design, and take even longer to implement. An organic way for 2 or more counterparties to get the benefits right away is stapling (I stole this from Dimitry at Modern Treasury). At a high level this involves:
Inserting a pointer (this could be a reference that’s privately understood like a guid, a URL that’s publicly resolvable, or something tokenized) in the statement descriptor
Both parties agree on a pointer format in advance
The sender system generates the pointer, “staples” it to the payment and the receiver system “unstaples” it, expands it into the richer context and translates it into something consumable by the various subsystems
The upside of this model is you don’t need to create a giant consortium of parties to agree in order to get the benefits. The downside is every counterparty pair might do things slightly differently which means a single entity might have to handle multiple types of business logic to handle a bajillion edge cases.
I'm going to whisper this very softly but...is this an actual crypto use case
Neat article
Industry or use case specific stapling standards could be viable