
August 2025: A Deep Research Agent for healthcare claims
Going 2x as deep into claims data with 1/10th the human effort, using a vertical deep research agent.

For the past year at Substrate, we’ve focused deeply on helping healthcare practices and billers get more efficient at AR follow up and denials management. While at Carbon I realized a frequent problem in AR is just understanding what is happening with a claim, or a queue/worklist of claims[1]. In the course of doing this, there are many different sources that a biller or RCM [2] operations team can use to get up to date. Some potential sources include:
the claim status transaction type (colloquially called the “277”)[3] available by via EDI,
the claim acknowledgement sent by the payer,
the Explanation of Benefits (EOB) or Electronic Remittance Advice (ERA or 835)
documents available in the lockbox, and more.
Often, a biller only needs one source to tell exactly what is wrong and what to do next, but the exact source might differ from claim to claim or queue to queue, and they don’t know which one they need for a specific claim until they see it. For some encounters the claim status is sufficient, for others you might need an EOB or the correspondence document that was sent. Less often, the biller needs to triangulate across multiple sources to get to ground truth.
With this in mind, we began by building browser agents to navigate payer portals for practices. The first thing a biller does is look up the claim in the portal; this will often have either everything the biller needs or a pointer to where they should look (which would again be just another browser tab). Next, depending on what they learned, they’d potentially look in other places; checking the patient’s eligibility to figure out if there was another payer that the claim should have been sent to, checking the EOB for the claim to get the payment information, and more. Ultimately this information drives a decision about what to do next. This process is incredibly tedious; it’s a lot of copy-pasting data between tabs, waiting for payer websites to load, cross referencing information, and then reasoning about why the claim is in its current state. No one enjoys it, and it’s a massive time suck for billing & RCM operations teams. Some organizations have whole teams who only do this. In others, every team is responsible for logging into the portal and looking up the claim themselves.
In theory, an RCM team should be able to achieve all this by utilizing the available EDI transaction for claim status (the 277). In practice, this only gets you part of the way there. 83% of insurance companies (2,900 out of 3,500) don't support automated claim status checks, forcing manual portal lookups anytime something goes wrong.
For the ones that do, you encounter myriad fidelity issues; everything from finding the exact payer to report on the claim, all the way to extracting sufficient signal about what to do next. The quality of data you get varies widely between payers and between different claims from the exact payer, and the richness available from a specific payer varies widely between 277/EDI transactions and what’s available to a human in the portal. I’ve long believed that payers often degrade the communication channels available to machines because they can get away with it, and providers are just as likely to blame their clearinghouse for any issues. It’s harder to degrade portals though (or other human interfaces) because then the humans can really complain and know who to blame. As a result, you see this disparity where human interfaces are incredibly privileged and have really rich data and functionality, while machine interfaces consistently lag behind. For example in comparing the 277 response and the portal data for the exact same encounter from United Healthcare (the largest and arguably the most technologically sophisticated healthcare company on Earth), you can on average extract 2x as many fields from the portal as you can from the 277 transaction (37 in the portal vs. 15 in the 277). Basically the machine interface only has half the depth as the human interface:
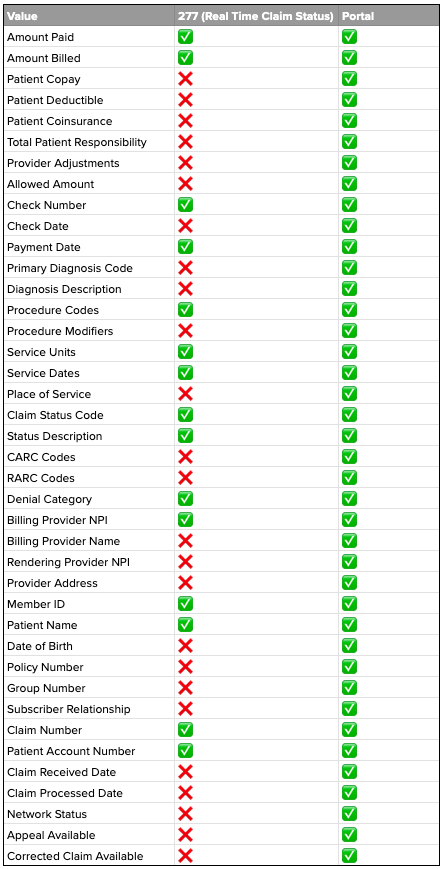
The worst part is this isn’t consistent; while the portal is always richer, the 277 might actually be sufficient for the problem you’re solving. You just don’t know until you see the results. And there are a handful of large payers (Medicare and Tricare in particular) that don’t support the 277 transaction type.
What this means in practice for a billing team is you spend lots of time hunting and sniffing around various places to piece together all the data about a claim. To understand what’s going on with a claim, you might spelunk through 5 separate tabs or applications; your EMR, PM, Payer Portal, Lockbox Portal, and payment posting system. Each unique interaction requires 2 - 4 minutes of clicking, copying, pasting, and waiting for a page to load (often only to find out the payer is down or something else you couldn't know in advance).
We built a vertical deep research agent that automatically checks all these sources simultaneously and synthesizes the results—like having a superhuman biller working 24/7.
Introducing the deep research agent for healthcare claims
To solve this, we developed the most comprehensive claim status product in the world. We did this by giving our agent all the tools that a human would have, and all the tools a machine would have. As a result we can access:
EDI transactions (mostly 277 real-time claim status and the 271 eligibility transaction, but can integrate others as needed)
Direct API connections to large payer interfaces like Availity and United
Browser agents for
Payer portals - this allows the agent to see exactly what a human would see when they log in. We utilize infra providers like Cloudcruise for this
Banks
Lockboxes
EMRs: this enables us to consolidate clinical data about the encounter (we utilize a combination of RPA, browser agents and computer use infra providers like Nen for this case)
Pretty much any system a human biller can log into
In addition, we’ve begun pulling in payer policies and contract data (including rates, cpt codes, requirements, and more) in certain cases, as well as extracting financial data directly from EOBs. These are extremely tedious tasks that (in many cases) would take a biller several minutes per claim to pull all together. We find all the data knowable about a claim, decide what to do with it, based on your rules/configuration, take actions on it in your system, and of course allow you to chat with it:
How it works
While traditional deep research agents often start with a freeform prompt and synthesize a ton of breadth, we start with your encounters and synthesize a ton of depth. You can get started with a thin demographic extract of the relevant encounters you want to investigate. The “thin” -ness of this is important. Many technology providers in the revenue cycle/claims space require practices to pull large amounts of extremely detailed claims data, and then spend time and effort normalizing the data into a format that allows them to run analytics. Our approach is the opposite - we request ~10 fields per encounter, retrieve the claims data from every source outside and inside the practice, and normalize it ourselves.

The beauty of this is that healthcare practices can start to see results within minutes. Almost any PM or EMR can generate this list of demographics quickly (we already interact with thousands of physicians and have yet to encounter a single EMR that can’t generate this).
To do the job, we need a few types of tools that are difficult to give a more generalized agent:
Open access tools
Open access tools are accessible on the open web, and definitionally accessible to a traditional deep research agent. These include data like payer policies, companion guides for EDI connections, NPI data, Medicare rates, and more.
Privileged access tools
These are tools where you’ll need API or EDI/Clearinghouse access to payer information about a specific encounter. This might be a claim status, patient eligibility or a claim acknowledgement. We currently use Stedi for EDI access, and have direct integrations into a handful of payers for privileged access. You can get access to these tools without specific credentials from the healthcare practice.
Credentialed access tools
These are tools where the agent needs the practice to grant access. The way to think about this as a healthcare practice is; “what’s the set of logins you’d give to a new hire on your billing team?” Access might be login credentials to payer portals or a practice management system or bank account, or might be internal documents like SOPs or payer contracts. These are effectively the same tools a human would use to investigate claims.
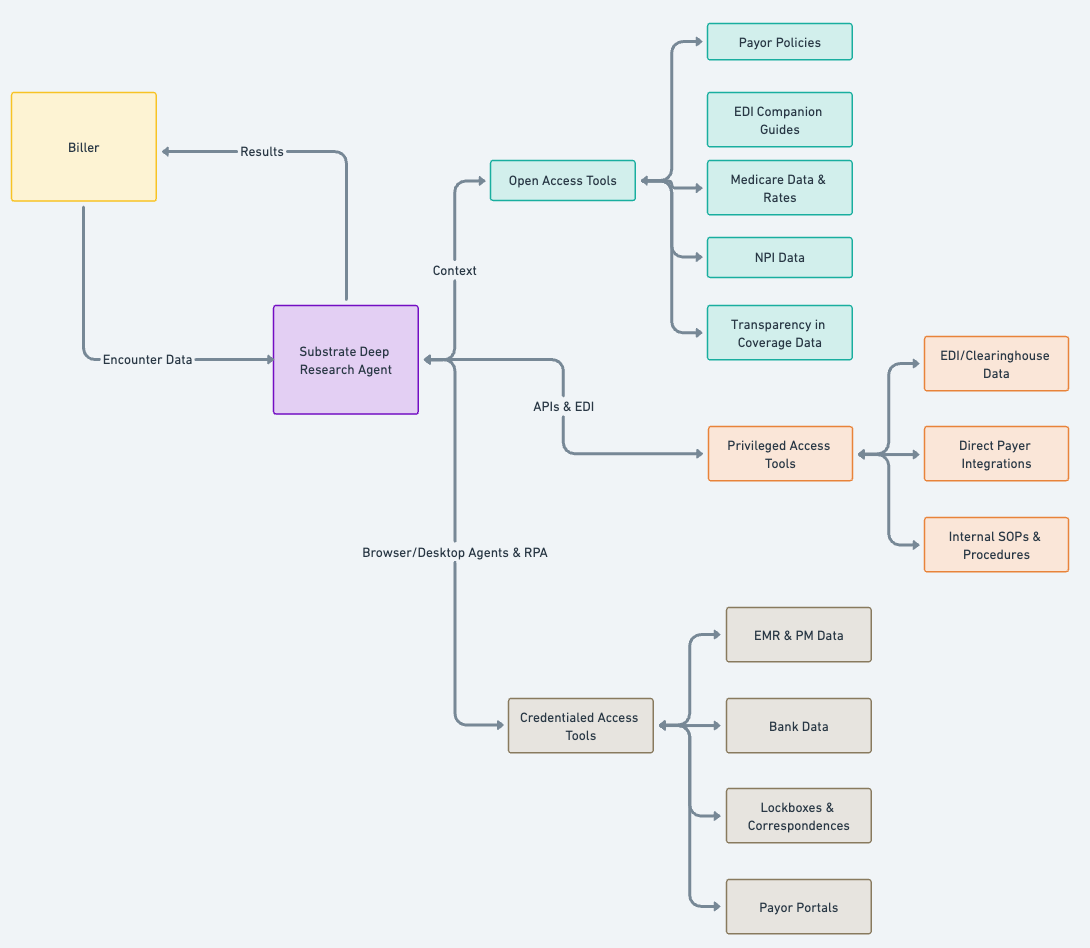
Our system then reconstructs your accounts receivable by seeing it the way insurance companies do—giving you the financial data that the insurance company has on file, about your claims. This involves giving the agent a deep suite of healthcare-specific tools that optimize first for getting any information on as many claims as possible, as much depth as possible on problem claims, and leveraging reasoning to interpret, and analyze the information available, and decide what tools to use next.
How we use this today
Today, we use this to enable clients to quickly understand which claims in their backlog need attention, and what to do about those claims. Using our deep research agent, they can answer questions like:
How many claims have been paid vs. not.
How much was paid on each claim, and when?
What’s the outstanding patient responsibility for this particular claim, or group of claims?
How many are outstanding or denied, and why?
Why was a particular claim denied?
Did the medical record support the coding available on the claim?
Which claims should I focus on?
Who could use this
We started out by building for the AR follow up use case (just tracking insurance claims that are somewhere between “submitted” and “paid”. Along the way, the ROI is clear: For each claim, every source they have to check is 3 - 4 minutes of human interaction time (not including reasoning about what decision to make). For every thousand claims you’d basically save a full time employee a week of detective work. We’ve already encountered several use cases for this approach:
Enabling practices & outsourced billers to monitor claims
Practices use us to monitor claims in their backlog; these include no-response claims (where you haven’t heard from a payer in a number of days) or denied or appealed claims. In this use case, we give you more data and cover more payers than available via EDI, and save your team the time they’d spend looking up these claims by hand.
Enabling practices to monitor their BPO
We’ve helped a number of practices that don’t have great visibility into how their BPO is doing measure how much is outstanding, by payer, and why. For these folks we provide out of the box denial trending to help measure their AR and quickly figure out where to focus and what questions to ask.
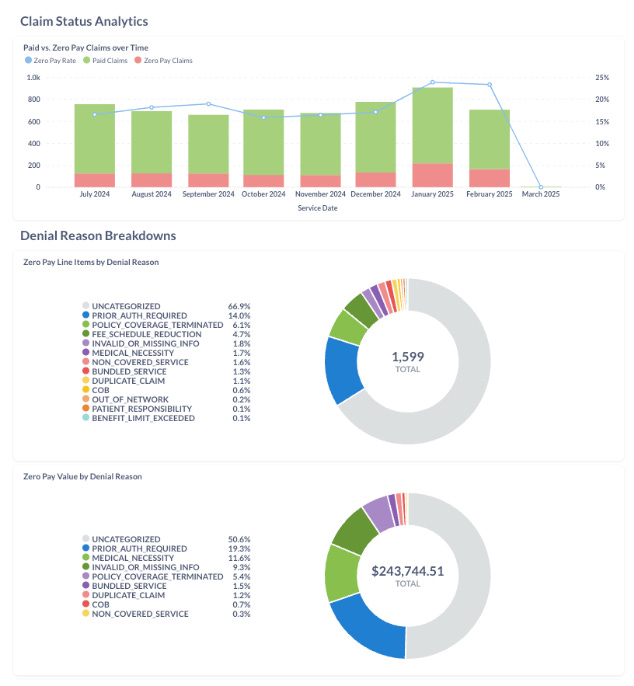
Payment Posting & Reconciliation
This one was surprising. In certain cases, it's become easier for practices to use us to extract payment information, patient responsibility and EOBs directly from the payer portal. This is due to a combination of things; some payers still send these details via paper, or a new provider coming into a practice might require a change in EFT enrollment, or something else. In these cases, we make it easy to go from “what’s going on with this claim” to “here’s an EOB you can use to post a payment” in just a few clicks.
Aged AR
If you are a healthcare practice or an outsourced biller or a large BPO, or you otherwise have a large backlog of claims that need investigation, our deep research agent can help you understand your AR in just a few days, with minimal people overhead.
Acquisitions & Transitions
More recently we’ve begun helping some practices get a crisp understanding of their AR as they transition between BPOs or from a BPO to bringing their RCM in house. For this problem set, it’s often far easier to rebuild the AR from the payer perspective than to make sense of your old system’s claims export and trying to smush it into your new system. For these folks, we make it easy to keep track of your AR as it changes hands. If you’re acquiring a practice and transitioning their claims, or you’re an outsourced biller and you’ve won a large client and you want to quickly get to the heart of what's happening with their AR, this is perfect for you. Think of it like claim status on steroids.
What comes next
To date, most of what we’ve given the agent access to are “read” actions. It performs lookups from several trusted sources and consolidates all the information to present and synthesize it for you.
Next, we’re going to do two things:
First, we’ll continue to expand the specific external tools it has access to. This will include pulling in items such as payer policies, payer contracts, contract rates, lockbox documents, and more. Our objective is to enable the agent to gather all the necessary information to draw a conclusion. More broadly, enriching the available toolset expands who can use it, and for what.
Second, we’re giving the agent “write” access. This will enable the agent to adjust & advance claims in your practice management system, including tasks such as adjustments, write-offs, actioning worklists, and adjusting queues.
More to come on this. If you’d like to work on this or think it you could use it, please reach out.
Thanks to Chet Montefering, Marlo DeLatorre, Inderpal Singh, Murad Salahi and Trent Lowe for reading this in drafts.
[1] Think of this as a way to group or cluster a number of claims that are in a similar state based on the information available. RCM operations leaders typically organize teams of people around a queue so they can build up context and expertise and execute the queues more quickly.
[2] Walking into your doctor’s office and use your insurance, is just the beginning of a complex and (often) long financial and operational process of the doctor getting paid. Your doctor submits a claim to your insurance company, which is essentially a detailed bill explaining what services were provided, what problems you presented with, which specific practitioner(s) saw you, where, and how much they cost. But unlike paying for groceries where you swipe a card and get an instant authorization, your doctor might wait months to even know if the insurance company received the claim. The only way to find out is for someone at the medical practice to manually hunt for answers: logging into insurance company websites, calling insurance call centers and piecing together fragments of information from different sources. For a typical practice managing thousands of claims across dozens of different insurance companies, this detective work consumes an insane amount of their billing staff’s time. Its like trying to track packages from 50 different shipping companies, each with their own tracking system, and most of them don't send you notifications when something goes wrong.
[3] Healthcare counterparties exchange data utilizing standardized electronic messages called EDI (Electronic Data Interchange) transactions, each identified by a three-digit code. Think of these as different types of automated conversations between healthcare providers and insurance companies:
The Eligibility Check (270/271): Before treating a patient, providers send a 270 transaction asking "Is this person’s insurance valid?" The payer responds with a 271 containing benefit details, copay amounts, and deductible information—essentially a digital insurance card check. Hilariously, the amounts the patient is responsible for often change after the claim is adjudicated, so even after collecting a patient’s payment upfront, providers often have to either bill or refund the patient for the difference after the claim is fully adjudicated.
The Claim Submission (837): After providing care, providers submit an 837 transaction—the actual bill containing diagnosis codes, procedure codes, provider information, and charges. This is the healthcare equivalent of mailing an invoice.
The Claim Status Inquiry (276/277): When weeks pass without payment, providers send a 276 transaction asking "What happened to my claim?" The payer (sometimes) responds with a 277 containing the claim's current status—pending, processed, denied, or paid.
The Payment Advice (835): When a payer actually pays a claim, they send an 835 transaction (Electronic Remittance Advice) explaining what was paid, what was denied, patient responsibility amounts, and adjustment codes explaining any differences from the billed amount. This is analogous to the EOB (Explanation of Benefits) that you might receive from your insurance company after the claim is adjudicated; the main differences are that the 835 is 1) Machine readable by default and 2) meant for the doctor not the patient to consume.
Sorry for the buzzword bingo.
This is awesome. I've been trying to do this with other use cases, specifically in biotech. What deep research agent are you using? I know ChatGPT can connect to Custom MCP Connectors (but I do not have pro). N8N can create custom workflows.
What are the options you've seen to have Deep research connected to APIs and your learnings building using that?