
April 2026: Everything is context
It’s evals all the way down


When we started building AI Agents for Revenue Cycle Management (RCM) 18 months ago, we had an inkling that a lot of what it took to be successful at RCM in the early stages would be inputs into an agent’s decision making. It took us over a year to get to the point where that was obvious, but now we’re there and I’m seeing it all over the place.
I’ll use our recently launched Claims Status agent as an example. When we started, the specific problems we would encounter weren’t obvious. We talked to several large healthcare organizations spending millions annually on AR follow up, who were seeing less than 15% success rates on their overall claim status infrastructure utilizing the clearinghouse EDI 276/277[1] infrastructure.
Our vision at the time was an agent that could use the same tools that a human could use, to solve the problem.
Perceived vs. Actual Problems
We thought the problems we would face would be just stringing different routes together and deciding what to use. For example, should you check United via Waystar, Change, or should you just call the payer via voice? Did all routes yield the same fidelity/quality of output that could help drive your next decision as a biller? Our initial design was around this concept.
The actual problems we faced, and the ones we focused on solving, were much more around data hygiene and internalizing each practices data, each payers model, and how those models map to each route (think of a route as a method of reaching the payer - there are a few truly digital methods like APIs and EDI interfaces, and a few manual ones like checking a portal and voice). Some payers store a claim using the provider tax ID, others on the provider’s NPI[2]. This means if you pick the wrong one, your lookup fails. You can sometimes discover these nuances by reading their EDI companion guides[3]. But often the only way you find out that you even have a problem is through trial and error (where each trial is espensive - you’re paying for human bandwidth, for compute, for the clearinghouse or for all 3. When troubleshooting the high failure rates experienced by customers, it became clear that:
Very often, the Electronic Health Record (EHR) used by a practice would store their claims data in a way that is difficult to export, interact with, and normalize. Sometimes this was a function of the technology being old, but more often as a function of EHRs by and large being an extremely customizable piece of software that moulds to each practices needs
Different payers have wildly differing ways they store claim data, multiple interfaces to look up a claim, and multiple sets of keys in each interface
Different payer interfaces (APIs, vs, Portals, vs EDI vs Voice) require different inputs to get to a claim
The exact same claim by the same payer might yield a different status or result or level of detail depending on the route you take (EDI vs browser vs voice) or the lookup method you choose (eg patient focused lookup vs date focused)
As an example - look at this claim (real claim, all PHI redacted). The first image is when the claim is looked up using the member id + group number combination:
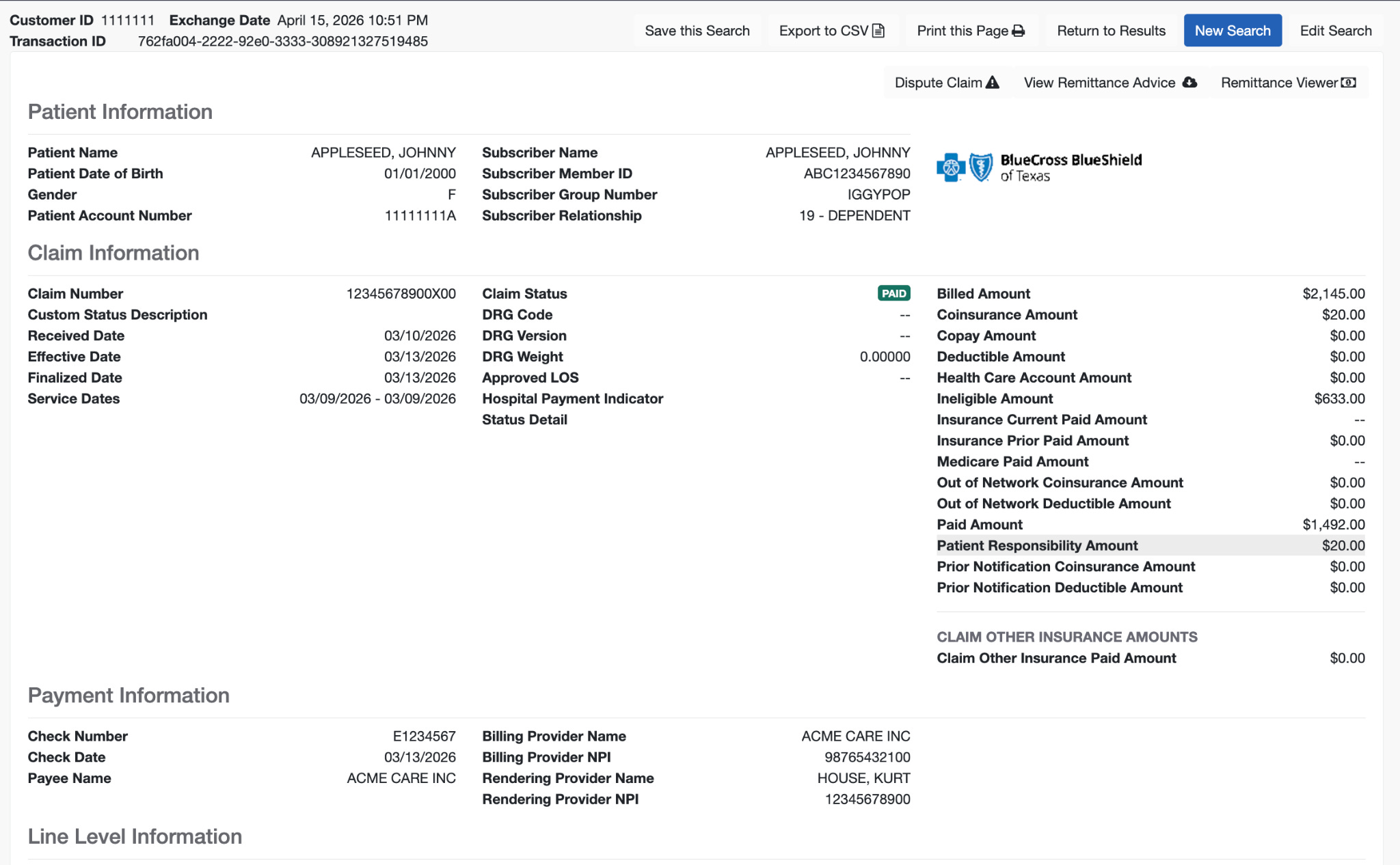
The second (below) is when the claim is looked up using the patient name + date of birth + member id.
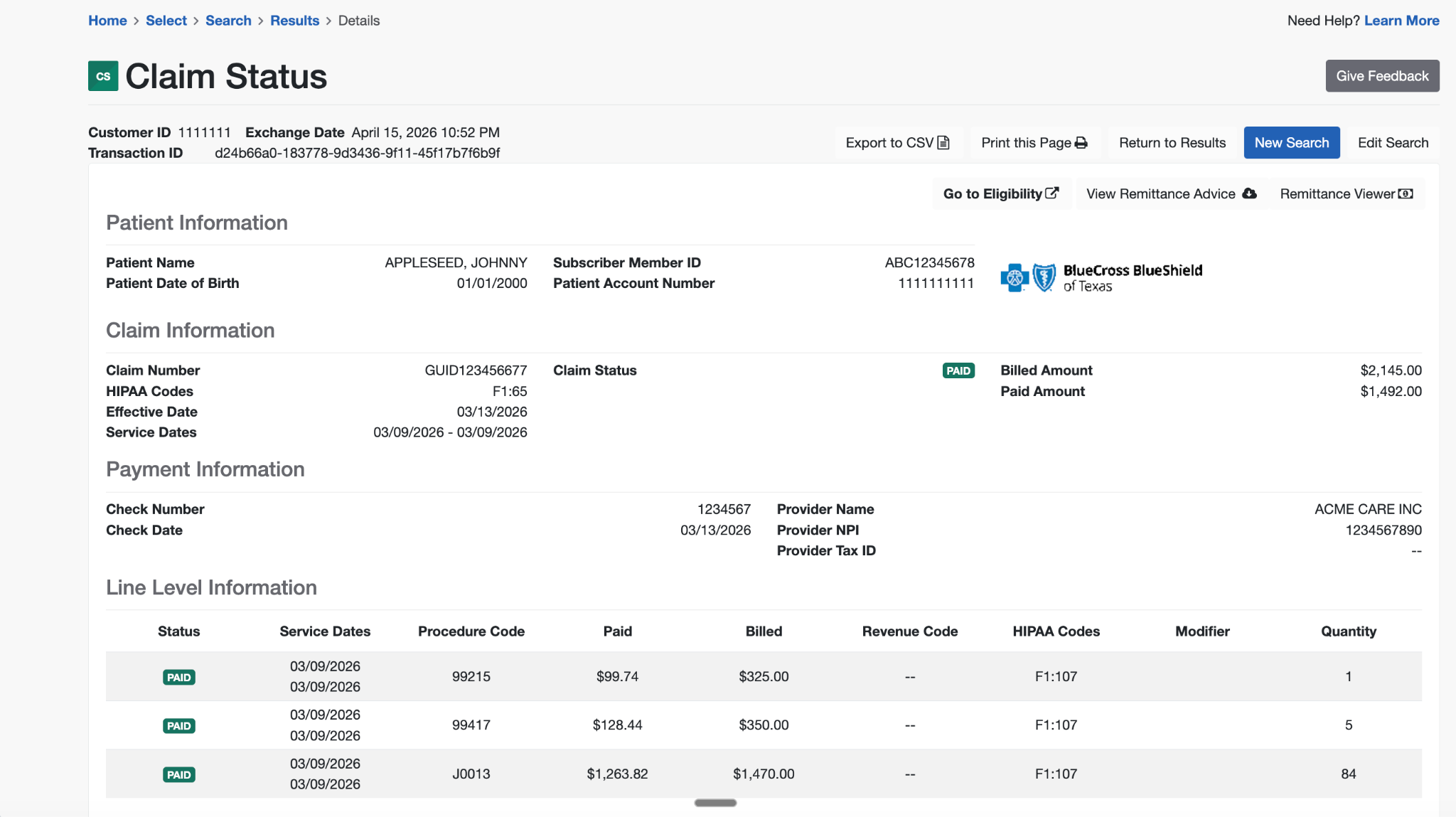
Both tell you generally what has happened with the claim, but one arbitrarily has two times more detail than the other. This matters all the time - the wrong lookup wastes time, and might direct your team to do the wrong action. Without this context (and other similar examples), we’d have designed the Substrate Claim Status Agent really differently.
After a few months spent doing these iterations by hand we realized a) an agentic approach to this part of the problems was required and b) all our prior artisanal iterations, historical successes and failures were just inputs for the agent to use.
Everything is context
Looking back, this insight was more correct than we realized. We used this approach to design the claim status agent (and attendant sub-agents) and the harness around them, it harnessprompts + context for the claims status agent to use. This approach has helped us get claim status success rates north of 60% and climbing. I now look at almost all the v1s and things we do by hand as context an agent will use one day.
This approach has yielded some happy surprises; for instance, there are cases where the health plan you’re trying to interact with can be reached through a route that’s not publicly legible. “Route” here means that the payers work together to process claims, or one payer provides claim processing infrastructure for the other. Some state medicaid payers, while not directly accessible through the 276/277 transaction interface, are technically accessible through publicly unrelated payers that you simply would never know to lookup. That is - if you queried Payer A directly via the 276/277 clearinghouse transaction, the transaction would fail, but if you queried (seemingly unrelated) Payer B with the exact same data, you’d get a successful response. Our Claim Status agent helped uncover these relationships, and in an ecosystem as entropic as healthcare - its super difficult to discover these things by hand.
Zooming Out
Viewed through this lens, without all this context we’d have made worse decisions (and the Claim Status Agent would have made systemically worse decisions as well). My read is that the companies and teams that have focused on going deep to get high quality outcomes in their core business/workflows, that are well labeled and consistently documented are better positioned to build better AI products than others. A good example of this is early Abridge - they shipped a consumer app (of which I was a very happy user) that patients used to record doctor visits. This approach brought them right into the appointment as a first party, and were exclusive to them and (with no inside knowledge of exactly how they used it) helped create a data headstart which in many ways persists till today.
Similarly at Carbon, we were able to create very proprietary data for our AI scribe, medical coding copilots and more, because we had core access to all the visit context - from the phone calls where the patient called in, to the claims sent to the payer, to payer responses, to provider feedback, to actual visits/encounters. In advance, we didn’t know how critical this all would be for making those products to be really high quality - we just knew that if we didn’t deliver outcomes (like high quality coding documentation to support payer audits) we’d be in trouble. But in hindsight, that initial focus on going deep to drive high quality outcomes led to (for example) a scribe with > 95% adoption within the clinics.
We’re hoping the same is true for Substrate.
Thanks to Jaren Glover, Dimitri Dadiomov & Kevin Kwok for reading the draft
[1] The 276/277 transaction set is an EDI (electronic data interchange) transaction that can be used by a provider, recipient of health care products or services, or their authorized agent to request the status of a health care claim or encounter from a health care payer.
[2] https://www.cms.gov/regulations-and-guidance/administrative-simplification/nationalprovidentstand